
The Hyperbolic Chamber - 12/12/2023
I took a break to get smarter.


It’s been a while. I haven’t written a blog in a long time but it has been a busy past few weeks of work and learning. So here I am reporting back on what I’ve been working on in my spare time while I’ve been away from the blog. This may be in more newsletter format because there is a lot. I’ll try to condense it the best I can.
Homelab Update
I am most proud of my homelab. There are many different services I have running on my homelab Kubernetes (k3s), PiHole, Wireguard, Nextcloud, and more. TrueNAS Scale is a great solution for deploying these services at the click of a button. However, I was tired of ‘ClickOps’ and wanted to learn more about the underlying infrastructure/configuration. My solution was getting XCP-NG and XenOrchastra running on my other NUC.
It’s Always DNS
A big thing I have been learning, which is involved in every configuration is DNS. Hosting internal and internet-facing applications, VPNs, and more involves a lot of networking. Over time networking setups become easy, but a lot of the issues that arise during deployments tend to fall on something networking-related.
K3S
My first goal was to use XCP-NG to get a Kubernetes cluster running at home. It can only help to know k8s, so I dove right in. K3S, a lighterweight, edge compute version of k8s is the solution I went with. Though k3s is lightweight, don’t mistake it for fake Kubernetes. Many companies run Kubernetes on edge using k3s. Chick-fil-A runs a three-node k3s cluster in all their stores, this podcast explains more of their use case and architecture. I will not bore you with the configuration of ingress controllers, master and worker nodes, etc. but after much deliberation, I have a two-node cluster (which I will expand once I get more compute) and nginx running as a test. I plan to deploy real applications that I write onto the cluster with time (I’ll get to that later).

AWS Workmail Migration
I have an affinity for moving things off of the cloud. More so, I have an affinity for saving money. AWS Workmail costs $4 per user/month for a single organization (think domain). I have 4 domains. Even if I were to host one mailbox per domain I am paying $16 per month, or $192 per year. I love email and all but not this much. Thanks to shared knowledge, I found Purely Mail, a trusted service where email is hosted for only $10 per year! After moving changing many DNS records and testing deliverability I am of Workmail for good.
Bonus: You can use pay-as-you-go with Purely Mail. After turning it on, Purely Mail currently costs me $0.17 per month, which will cost me just over $2 per year, which means my $10 deposit will last for nearly 5 years. A big step up from $192 per year.
Backups
I can’t stress to you enough how important backups are. Thanks to TrueNAS my Macbook is backed up to a Time Machine SMB share every day. TrueNAS is backed up to Backblaze B2 Cloud Storage every day as well. Recovering from backups will be tested quarterly. You never know when things may just hit the fan, and since I am now hosting my data in my cloud instead of someone else’s, my data must be available. You don’t take on this burden using something like Google Drive or Dropbox, but I don’t take on the burden of having my data scanned and indexed by big tech.
Extras
Needless to say, I am working on a lot of different things. Extracurricular homelabbing includes automation for always-on VPN for my phone, writing a script to get unreleased music onto streaming services, cloning and hosting websites in minutes, learning VIM, and whatever else comes to mind.
Project Update
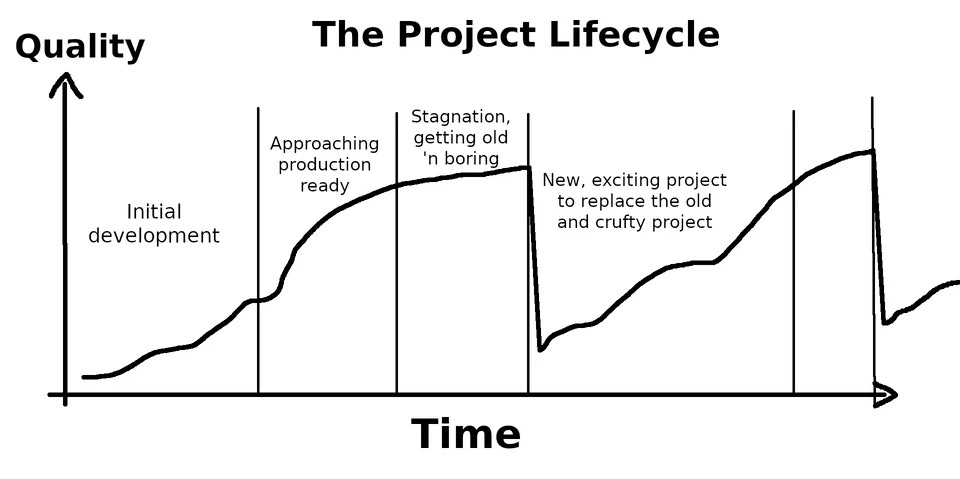
I am no different when it comes to the personal project lifecycle seen above. My project graveyard runs deeeeeep. I don’t feel bad though because it is all in the name of learning.
Right now my project is writing a To-do-list application using GO. The purpose of this is to learn GO, see what it looks like to build a full-stack app, containerize my app, build a CI/CD pipeline, and run it on k3s with ingress at home (full circle). I’ve run into many issues so far, mainly with the pipeline, but I currently have an application running with a basic HTML frontend, GO API, and Postgresql backend.
Here is here is the code for the API, starting with importing packages, connecting to Postgres, and defining the API endpoints with their help functions:
package main
import (
"database/sql"
"log"
"net/http"
"github.com/gin-gonic/gin"
_ "github.com/lib/pq"
)
type task struct {
ID string `json:"id"`
Task string `json:"task"`
Urgency string `json:"urgency"`
Hours float64 `json:"hours"`
Completed bool `json:"completed"`
}
type completed struct {
ID string `json:"id"`
Task string `json:"task"`
}
var db *sql.DB
func main() {
var err error
dbConnectionString := "postgres://username:password@10.0.0.0:5432/postgres?sslmode=disable"
// Open a connection to the database
db, err = sql.Open("postgres", dbConnectionString)
if err != nil {
log.Fatal(err)
}
router := gin.Default()
router.LoadHTMLGlob("templates/*")
router.GET("/", func(c *gin.Context) {
c.HTML(http.StatusOK, "index.html", nil)
})
router.GET("/tasks", getTask)
router.GET("/tasks/:id", getTaskByID)
router.DELETE("/delete/:id", deleteTask)
router.POST("/tasks", addTask)
router.GET("/completed/:id", completeTask)
router.POST("/completed/:id", addToCompletedTable)
router.GET("/completed", getCompletedTasks)
router.Run("0.0.0.0:8080")
}Then all the helper functions for the different endpoints, including getTask, addTask, deleteTask, completeTask, and more:
func getTask(c *gin.Context) {
c.Header("Content-Type", "text/html")
rows, err := db.Query("SELECT * FROM tasks")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
var tasks []task
for rows.Next() {
var t task
if err := rows.Scan(&t.ID, &t.Task, &t.Urgency, &t.Hours, &t.Completed); err != nil {
log.Fatal(err)
}
tasks = append(tasks, t)
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
c.HTML(http.StatusOK, "tasks.html", tasks)
}
func addTask(c *gin.Context) {
var newTask task
if err := c.BindJSON(&newTask); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": "Invalid Request Payload"})
return
}
stmt, err := db.Prepare("INSERT INTO tasks(task, urgency, hours, completed) VALUES($1, $2, $3, $4)")
if err != nil {
log.Println("Error preparing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
defer stmt.Close()
if _, err := stmt.Exec(newTask.Task, newTask.Urgency, newTask.Hours, newTask.Completed); err != nil {
log.Println("Error executing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
c.JSON(http.StatusCreated, newTask)
}
func deleteTask(c *gin.Context) {
id := c.Param("id")
stmt, err := db.Prepare("DELETE FROM tasks WHERE task_id = $1")
if err != nil {
log.Println("Error preparing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
defer stmt.Close()
if _, err := stmt.Exec(id); err != nil {
log.Println("Error executing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
c.IndentedJSON(http.StatusOK, gin.H{"message": "Task deleted"})
}
func getTaskByID(c *gin.Context) {
id := c.Param("id")
rows, err := db.Query("SELECT * FROM tasks WHERE task_id = $1", id)
if err != nil {
log.Fatal(err)
}
defer rows.Close()
var t task
for rows.Next() {
if err := rows.Scan(&t.ID, &t.Task, &t.Urgency, &t.Hours, &t.Completed); err != nil {
log.Fatal(err)
}
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
c.IndentedJSON(http.StatusOK, t)
}
func completeTask(c *gin.Context) {
id := c.Param("id")
stmt, err := db.Prepare("UPDATE tasks SET completed = true WHERE task_id = $1")
if err != nil {
log.Println("Error preparing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
defer stmt.Close()
if _, err := stmt.Exec(id); err != nil {
log.Println("Error executing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
c.IndentedJSON(http.StatusOK, gin.H{"message": "Task completed"})
}
func addToCompletedTable(c *gin.Context) {
id := c.Param("id")
stmt, err := db.Prepare("INSERT INTO completed(task) SELECT task FROM tasks WHERE task_id = $1")
if err != nil {
log.Println("Error preparing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
defer stmt.Close()
if _, err := stmt.Exec(id); err != nil {
log.Println("Error executing SQL statement:", err)
c.JSON(http.StatusInternalServerError, gin.H{"error": "Internal Server Error"})
return
}
c.IndentedJSON(http.StatusOK, gin.H{"message": "Task added to completed table"})
}
func getCompletedTasks(c *gin.Context) {
c.Header("Content-Type", "application/json")
rows, err := db.Query("SELECT * FROM completed")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
var tasks []completed
for rows.Next() {
var t completed
if err := rows.Scan(&t.ID, &t.Task); err != nil {
log.Fatal(err)
}
tasks = append(tasks, t)
}
if err := rows.Err(); err != nil {
log.Fatal(err)
}
c.IndentedJSON(http.StatusOK, tasks)
}
The SQL tables are created with these create statements:
CREATE TABLE tasks (
task_id SERIAL PRIMARY KEY,
task varchar(256) NOT NULL,
urgency varchar(10) NOT NULL DEFAULT 'Low',
hours numeric(3,1),
completed boolean NOT NULL DEFAULT false
);
CREATE TABLE completed (
id SERIAL PRIMARY KEY,
task varchar(256) NOT NULL,
foreign key (task) references tasks (task)
);There are currently two HTML files that serve as the landing page and page returned when querying the getTasks function:
I’m going to build a much better & prettier UI with time do not fear.
I also wrote an additional Python script that will run as cron to parse the tasks table for completed tasks and move them to the completed table while deleting them from the tasks table. If I ever want to smell the roses one day I can query the completed table for everything I’ve gotten done:
import requests
base_url = "http://10.0.0.0:8080/tasks/"
r = requests.get(base_url)
r = r.json()
completed = [(task['id'], task['completed']) for task in r]
for val in completed:
base_url = "http://10.0.0.0:8080/completed/"
if val[1] == True:
r = requests.post(f'{base_url}{val[0]}')
print(r)
base_url = "http://10.0.0.0:8080/delete/"
r = requests.delete(f'{base_url}{val[0]}')
print(f"Task {val[0]} is completed and has been moved to the completed task table.")
else:
print(f"Task {val[0]} is not completed yet.")Yes, I know someone or some company has done this much better than I have but as I said, this is all in the name of learning.
Next Steps
As time progresses, my next steps for this project will be:
Containerization
Build CI/CD pipeline
Run on home k3s cluster
Make a more appealing UI
I can’t guarantee there will be another blog post soon, but I can say that there will be another when progress is made.
Closing
There is always more learning that can be done. A big thank you goes to those who give me new ideas, challenges, projects, and more. Though I haven’t been able to document all of the learning and growth, it has been exponential over the last few months and I’m excited for what is in store. Thank you for reading and see you soon!